

I’m currently playing around with elasticsearch, building a pipeline to ingest and modify millions of documents. While I’m still in the early, experimental stages I am tweaking my code then running my indexing script, only to find, a million documents later, that I need to make a change.
At this stage, making a change means, deleting all the documents and re-indexing them all. It’s really not best practice. What I need is some sample data - not all the data, in order to run my tests, tweak, refine and iterate.
My source data is dumped from an internal museum API and consists of compressed batches of object data held as new line json data. Each compressed bz2 file contains details of about 50,000 museum objects and I have about 25 files to wade through.
I know there are some interesting documents in there, I even have their system numbers (or IDs) but finding the choice objects in the data haystack and extracting them into their own sample data file has been a challenge.
Imagine 1.2m records that look a little bit like this:
{"title":"A photo","objectType":"photograph","placesOfOrigin":[{"place":{"text":"England","id":"Z23"},"association":{"text":"made","id":"X2"},"note":""}],"summaryDescription":"A fine thing","techniques":[{"text":"photography","id":"A2"}],"collectionCode":{"text":"Photography","id":"THES1"},"systemNumber":"123"}
{"title":"A photo frame","objectType":"picture frame","placesOfOrigin":[{"place":{"text":"England","id":"Z23"},"association":{"text":"made","id":"X2"},"note":""}],"summaryDescription":"Another fine thing","techniques":[{"text":"photography","id":"A2"}],"collectionCode":{"text":"Photography","id":"THES1"},"systemNumber":"1234"}
{"title":"A photo album","objectType":"photograph album","placesOfOrigin":[{"place":{"text":"England","id":"Z23"},"association":{"text":"made","id":"X2"},"note":""}],"summaryDescription":"And Another fine thing","techniques":[{"text":"photography","id":"A2"}],"collectionCode":{"text":"Ironwork","id":"THES1"},"systemNumber":"12345"}
But then I was introduced to jq a command line json processor, which enables you to select elements from a json file and save to a new file.
Using the jq playground I can experiment with the json file I shared above and extract only the lines where the systemNumbers are either “1234” or “12345”:
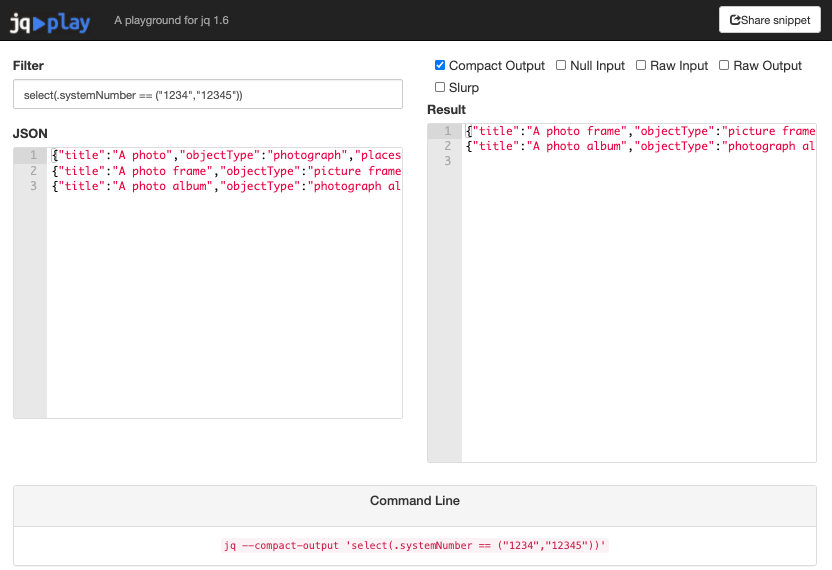
You can click the image above to experiment in the playground. It constructs the command line instruction:
jq --compact-output 'select(.systemNumber == ("1234","12345"))'
If you wanted to extract documents based on a nested field value, jq will again come to the rescue but you may have to do the tutorial or RTFM (aka Stack Overflow) for assistance as your demands increase in complexity.
Here’s another simple example from my data where I want to extract only objects in the Photography collection - which requires me to search within a nested field.
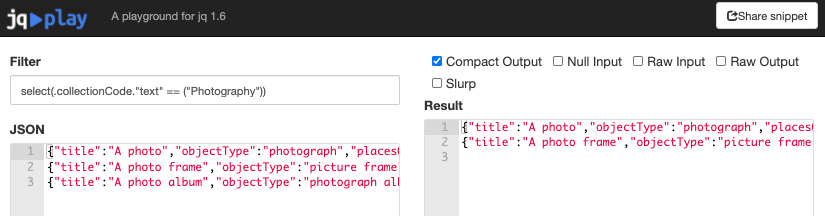
So bringing this all together, if I want to search through a folder of multiple compressed files and output a sample file with only the selected systemNumbers, my linux command would look something like this:
bzcat *.bz2 | jq -c 'select(.systemNumber == ("O1399609","O40025","O9138","O1281589"))' >> test_objects.jsonl
Comments